使用Spring AI与Pinecone实现RAG:实践指南
· 阅读需 5 分钟
引言
检索增强生成(RAG)已成为构建结合信息检索与生成式语言模型的AI应用的强大技术。本指南演示如何利用Spring AI和Pinecone向量数据库实现RAG系统,特别适用于创建文档问答机器人。
什么是RAG?
RAG包含两个核心组件:
- 检索:通过语义搜索从知识库中查找相关信息
- 生成:基于检索结果使用语言模型生成上下文响应
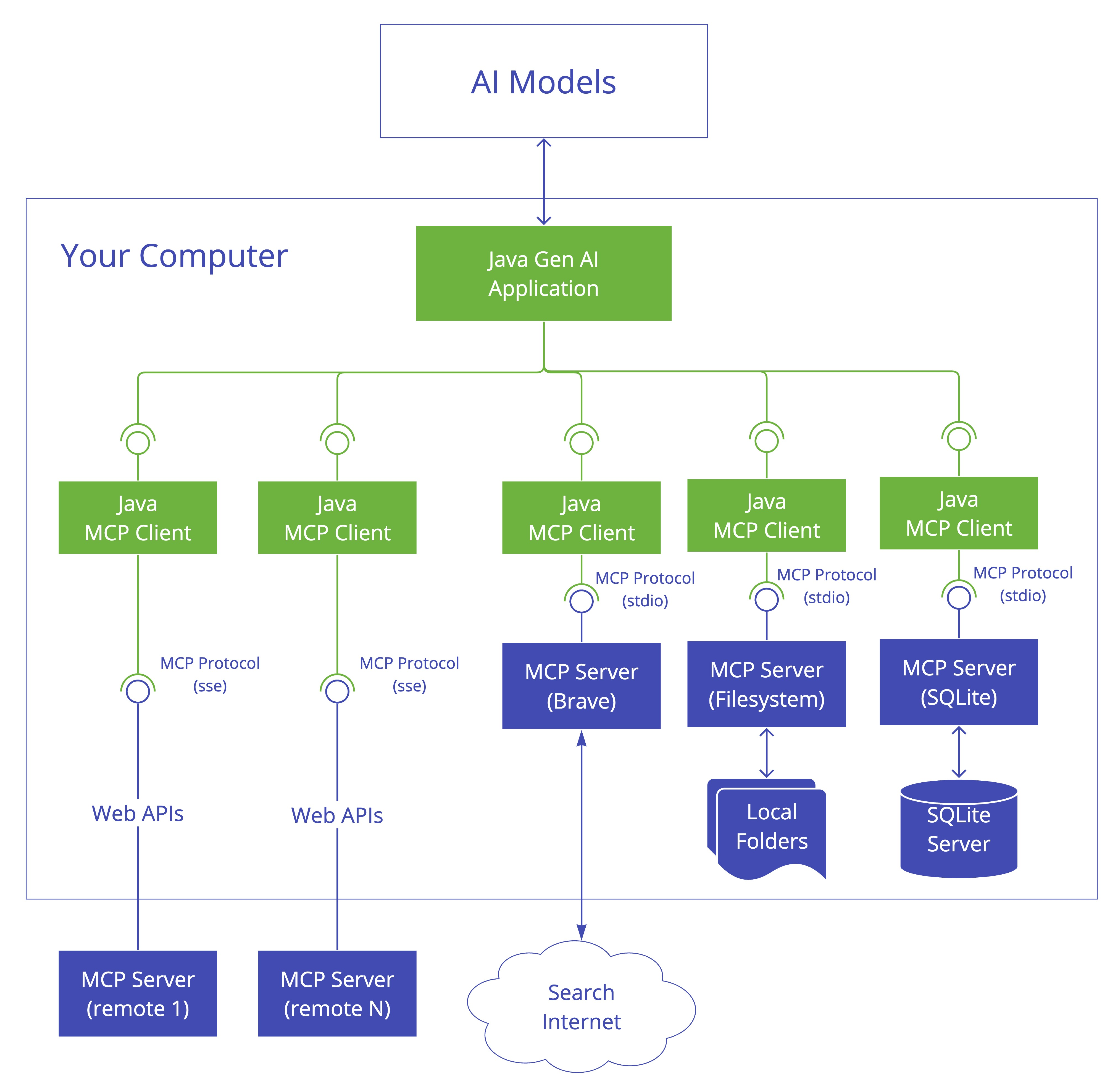
系统架构
[文档网站] → [爬虫] → [分块处理] → [Pinecone向量数据库]
↑
[用户提问] → [Spring AI] → [语义搜索] → [LLM生成] → [响应]
前置条件
- Pinecone账号(提供免费版)
- Spring Boot应用(推荐3.x版本)
- 向量数据库基础知识
实现步骤
1. Pinecone集成配置
Gradle依赖
implementation "org.springframework.ai:spring-ai-pinecone-store-spring-boot-starter"
配置文件(application.yml)
spring:
ai:
vectorstore:
pinecone:
apiKey: ${PINECONE_API_KEY}
environment: ${PINECONE_ENV}
index-name: ${PINECONE_INDEX}
project-id: ${PINECONE_PROJECT_ID}
2. 文档处理流水线
网页爬虫实现
public class DocumentationScraper {
private final Set<String> visitedUrls = new HashSet<>();
private final String baseDomain;
public DocumentationScraper(String baseUrl) {
this.baseDomain = extractDomain(baseUrl);
}
public List<Document> scrape(String startUrl) {
List<Document> documents = new ArrayList<>();
scrapeRecursive(startUrl, documents);
return documents;
}
// 包含URL标准化、同域名检查、内容提取等完整实现
...
}
文档分块服务
@Service
public class DocumentationService {
private final VectorStore vectorStore;
private final TokenTextSplitter textSplitter;
public DocumentationService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
this.textSplitter = new TokenTextSplitter(
2000, // 技术文档的理想分块大小
300, // 最小分块尺寸
100, // 上下文保留的重叠区域
15, // 每页最大分块数
true // 保持文档结构
);
}
public List<Document> processDocument(String content, Map<String, Object> metadata) {
Document originalDoc = new Document(content, metadata);
List<Document> chunks = textSplitter.split(originalDoc);
// 增强元数据以优化检索
for (int i = 0; i < chunks.size(); i++) {
chunks.get(i).getMetadata()
.put("chunk_number", i)
.put("total_chunks", chunks.size());
}
return chunks;
}
}
3. 知识库初始化
数据加载REST端点
@RestController
@RequestMapping("/document")
@Tag(name = "AI模块API")
public class DocumentController {
private final DocumentationService documentationService;
@PostMapping("/load-data")
public ResponseEntity<String> loadDocumentation() {
documentationService.scrapeAndStoreDocumentation("https://docs.openwes.top");
return ResponseEntity.ok("文档加载成功");
}
}
4. 在对话补全中实现RAG
@Service
public class ChatService {
private final ChatModel chatModel;
private final VectorStore vectorStore;
public String generateResponse(String query) {
SearchRequest searchRequest = SearchRequest.defaults()
.withTopK(5) // 检索5个最相关分块
.withSimilarityThreshold(0.7);
return ChatClient.create(chatModel)
.prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore, searchRequest))
.call()
.content();
}
}
最佳实践
-
优化分块策略:
- 技术文档:1500-2500 tokens
- 叙述性内容:500-1000 tokens
- 保留100-200 tokens重叠区域维持上下文
-
增强元数据:
metadata.put("document_type", "API参考");
metadata.put("last_updated", "2024-03-01");
metadata.put("relevance_score", 0.95);
- 混合搜索:
SearchRequest hybridRequest = SearchRequest.defaults()
.withTopK(5)
.withHybridSearch(true)
.withKeywordWeight(0.3);
- 提示词工程:
PromptTemplate template = new PromptTemplate("""
根据以下上下文回答问题:
{context}
问题:{question}
如果不知道答案,请回答"我不知道"。
""");
性能优化
- 缓存:对高频查询使用Redis缓存
- 异步处理:使用
@Async处理文档摄入 - 批量处理:按50-100的批次处理文档
评估指标
| 指标 | 目标值 | 测量方法 |
|---|---|---|
| 检索准确率 | >85% | 人工评估 |
| 响应延迟 | <2秒 | 性能测试 |
| 用户满意度 | >4/5分 | 反馈问卷 |
结论
本实现展示了如何构建生产级RAG系统,主要优势包括:
- 针对文档查询提供精准的上下文感知响应
- 可扩展的向量搜索能力
- 与现有Spring应用的轻松集成
后续计划
- 实现用户反馈机制:
@PostMapping("/feedback")
public void logFeedback(@RequestBody FeedbackDTO feedback) {
// 存储反馈用于持续改进
}
- 添加查询模式分析仪表盘
- 实现定期文档自动更新
项目参考:完整实现已发布在GitHub的module-ai包中,欢迎贡献代码和反馈意见!